Поиск похожего изображения
Небольшой отчет о создании приложения KawaiiSearch — поиска похожих фотографий с помощью сверточной нейросети и kNN
tl;dr; Качаем фотографии из интернетов. Натренированной нейросетью VGG19 вычисляем 4096-мерные вектора каждого изображения. Косинусной метрикой находим ближайшего соседа к целевой картинке. Получаем наиболее похожие картинки в каком-то смысле. Profit!
Source code.
Введение
Еще каких-то 5 лет назад, чтобы сделать свой поиск по картинкам, приходилось погружаться в тонкости машинного зрения. Нужно было придумывать то, каким образом преобразовать картинку в некоторый индекс, отпечаток, по которому можно найти другую, похожую на неё. Судя по всему, для этих целей могли использовать перцептивные хеши и вариации, разные преобразования характеристик изображений и даже каскады Хаара. В общем, всё это напоминало классические алгоритмы эпохи до машинного обучения, когда исследователям основываясь на их восприятии самим приходилось придумывать некоторые модели. Это всё безумно интересно и серьезно, можно защитить не один диплом и диссертацию. Но что примечательно, сейчас существует достаточно простой способ для построения своего собственного движка поиска похожих картинок и начать решать свои бизнес задачи немного проще, чем это было раньше.
Что такое “похожие” изображения

Прежде чем мы рассмотрим существующие подходы, необходимо правильно поставить вопрос — определить метрику похожести изображений. Но проблема подстерегает нас сразу, так как эта метрика может отличаться от задачи к задаче. Например, нам нужно находить исходное изображение по черно белому экземпляру. А может, необходимо находить картинки близкие по цветовой гамме. Возможна и постановка задачи, когда похожими считаются изображения со схожими формами объектов. А будет ли похожи фотографии одной и той же собаки в разных ракурсах или похожи фотографии разных собак, но в одном ракурсе.
Как видите, есть некоторые трудности в постановке задачи. Обычно даже не говорят, что две фотографии похожи, а рассматриваю некоторую величину похожести от, скажем, нуля — совершенно похожи, до бесконечности — совершенно не похожи. Измерение этой величины будет зависеть от той формы индексов, которые будет давать некоторый алгоритм; это может быть расстояние Хемминга или расстояние между точками в многомерном пространстве, или ещё что-то. Выбор метрики естественно будет влиять на результат не меньше, чем сам алгоритм поиска признаков в изображениях.
Обзор существующих классических решений
Если посмотреть на обычные алгоритмические методы сравнения изображений, то в основном всё сводится к вычислению некоторой хеш функции над изображением, а потом вычислению расстояния, например, Хэмминга между двумя значениями хешей. Чем меньше расстояние, тем больше картинки похожи между собой.
Далее начинается типичный для алгоритмических моделей путь выбора некоторой магической функции, которая будет сохранять в себе похожесть изображений. Один из примеров таких функций — это перцептивный хеш. В этом подходе с помощью дискретного косинусного преобразования оставляют так называемые нижние частоты, в которых сконцентрировано больше информации о форме изображения, чем о его цветовых характеристиках. В итоге большое изображение превращается в 64-битный хеш.
Есть еще несколько алгоритмов, даже на основе каскадов Хаара, но в результате так или иначе, алгоритм очень сильно страдает от преобразований над изображением: от поворотов, отражений, изменений размера, модификации цветности. Но тем не менее они очень быстро работают. Их можно использовать для поиска дубликатов с незначительными искажениями. Но для поиска изображениях, в которых “похожие” определяются в том смысле, что на них изображены коты, а не собаки, алгоритмы этого типа не подходят, да в принципе этого от них и не требуют. Забавно, что еще в 2011 году в комментариях к статьям писали, что невозможно написать такой алгоритм для кошек-собак.
Предлагаемый подход весьма наивный и простой, основывается на использовании машинного обучения и нейросетей. Так сразу в лоб и не совсем понятно чему надо обучать модель. Мы сами не можем сформулировать понятие “похожесть”. Тем не менее есть способ, и для его использования нам понадобится для начала решить задачу классификации.
Классификация изображений
На качественно ином уровне задачу классификации изображений начали решать с 2013 года. Тогда на наборе данных ImageNet пробили барьер в 15% ошибок классификации тысячи видов объектов. С тех пор за 5 лет было спроектировано и натренированно очень много разных моделей нейросетей, и был пробит барьер в 5% ошибок. Самыми успешными из них считаются: VGG16, ResNet50, Inception, GoogLeNet и много других. Большинство их них построено на основе свёрточных нейросетей.
На рисунке вы можете посмотреть как выглядит схематически архитектура VGG16.
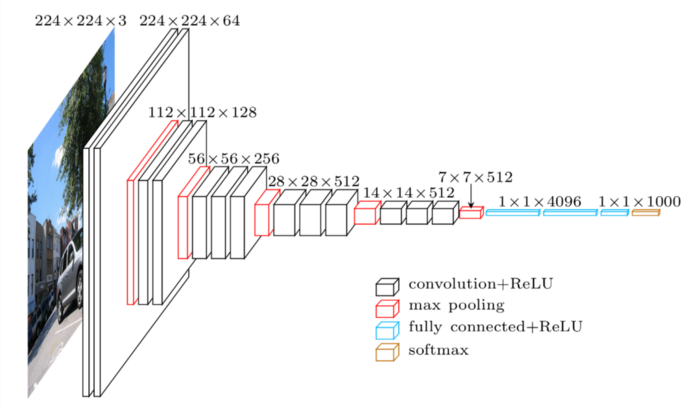
Слои нейросети на изображении состоят из набора разных фильтров-сверток. Каждый из фильтров отвечает за поиск определенного шаблона, и когда он находит некоторый участок изображения, в котором есть этот узор, то фильтр посылает сигнал в следующий слой. В свою очередь сигналы предыдущего слоя составляют новое изображение для следующего слоя. На рисунке архитектуры VGG16 вы можете видеть, что сначала было цветное RGB изображение размера 224x224 пикселей с 3 каналами(red, green, blue). Потом после прохода первого слоя сверток у нас получилось изображение размера 224x224 пикселей с 64 каналами. Эти каналы уже представляют не цвета, а результаты работы каждого из 64 фильтров-свёрток. И так далее, до изображения 7x7 пикселей с 512 каналами.

Строя каскады свёрточных слоёв и обучая модель, вы получаете слои, содержащие в себе абстракции изображений. Первые слои в себе могут содержать мелкие детали: линии. Далее идут комбинации деталей — фигуры. Следующие слои уже могут содержать формы, а в конце целые объекты.
 Feature Visualization of Convnet trained on ImageNet from [Zeiler & Fergus 2013]
Feature Visualization of Convnet trained on ImageNet from [Zeiler & Fergus 2013]
Обратите внимание еще на одну интересную особенность свёрточных слоев в этой модели: каждый следующий слой “толще”, так как в нём больше фильтров, но “меньше”, так как изображение специально уменьшают с помощью операции MaxPooling (субдискретизация). Используют этот прием по следующей причине: важнее факт детекции некоторого признака-объекта, чем знание точного расположения этого объекта на изображении. Именно поэтому берут максимум внутри небольшого окошка, тем самым создавая карту расположений признаков.
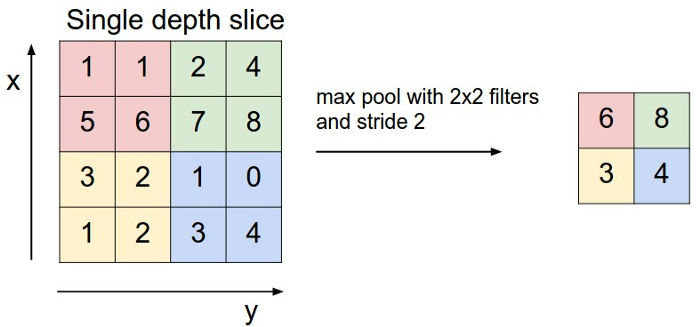 Max Pool 2x2, http://cs231n.github.io/convolutional-networks/
Max Pool 2x2, http://cs231n.github.io/convolutional-networks/
Ближе к выходу модели у нас имеется маленькое изображение — карта признаков размера 7x7 пикселей с 512 фильтрами. По этой трёхмерной карте всё еще невозможно сделать предсказания классов объектов на изображении — котик или собака. Для того чтобы перейти уже к предсказаниям классов, эту карту укладывают на плоскости с помощью операции Flatten и соединяют с полносвязным скрытым слоем из 4096 нейронов. А дальше классическая схема: еще один скрытый слой с 4096 нейронами и выходной слой с 1000 нейронами, каждый из которых выдает вероятность принадлежности к одному из 1000 классов в задаче ImageNet.
Fine Tuning и переиспользование модели
Как оказалось, сети обученные на данных ImageNet можно переиспользовать для других задач компьютерного зрения. Например, у нас задача отличать кошку от собаки. Вам не надо создавать свою модель CatDogVGG, искать миллионы картинок и обучать с нуля сеть. Всё куда проще! Вы берёте предобученную модель VGG, срезаете последние полносвязные слои нейронов, отвечающие за финальную классификацию(да, так можно), оставляя только внутренние 4096 нейронов, которые соединяете со своими 2 нейрона для выхода кошка-собака. Получается, что вам нужно будет только дообучить модель этим 2*4096 связям, что делается легко и быстро.
Какой физический смысл в срезании последнего слоя сети и подстановки нового? Оказывается, что все слои свертки внутри себя заключают способность “понимать” изображение. А поскольку обучение происходило на тысяче разных классов, то и обобщающая способность этих слоев достаточно сильная. В итоге внешние 4096 нейронов на самом деле выдают вектор характеристик(признаков) любого изображения в целом. Поэтому для того чтобы проходила наша классификация, отличная от изначальной, нам остается дообучить нейросеть только и только переводить этот 4096-мерный вектор в наш вектор предсказаний принадлежности классов, не меняя существующую глубокую свёрточную сеть.
Подобный финт можно провернуть не только с VGG, но и с другими свёрточными архитектурами распознавания изображений. Для этой цели в библиотеке Keras есть даже специальные конструкты, которые вы можете изучить это в разделе keras-applications. Распознавание образов еще никогда не было таким простым!
Поиск похожих изображений с помощью нейросети
Как мы поняли из предыдущего параграфа, срезанная нейросеть производит по своей сути извлечение признаков из изображения и переводит изображение в осмысленный вектор. Получение такого вектора раньше требовало экспертной оценки и придумывания очередного алгоритма хеширований. Полученные теми методами вектора (64-битные хешсуммы) заключали в себе информацию, в лучшем случае, о контурах и простых формах в целом. Нейросеть же даёт как минимум 4096-мерное представление, в котором заключена и форма, и цвет, и целые объекты.
Хорошо, нами получен вектор признаков изображения, что мы делаем дальше? Считать расстояние Хэмминга, как мы это делали с хешами, тут бессмысленно. Здесь мы должны использовать другой подход. Представьте, каждый из векторов куда-то направлен в пространстве, это направление характеризует изображение. Если мы посчитаем вектора для множества картинок, то логично предположить, что похожие картинки будут иметь вектора характеристик расположенные в пространстве близко. Отличной метрикой близости векторов в многомерном пространстве служит косинусная метрика, хорошо себя зарекомендовавшая в задачах классификации текстов.
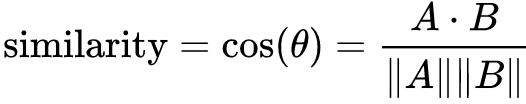 Косинусная метрика
Косинусная метрика
Чем меньше метрика, тем ближе объекты в векторном пространстве, тем больше похожи изображения по “мнению” нейросети.
Собираем модель как конструктор
Отлично, мы знаем теорию, знаем как получить представление нейросети об изображениях, знаем как сравнивать эти представления. Осталось дело за малым — собрать всё воедино.
Я предлагаю построить веб-приложение, похожее на Google Image Search. Для его построения нам понадобятся следующие библиотеки для Python3:
- Keras и Tensorflow для работы с нейросетями;
- Numpy (a.k.a np) для математических функций;
- Sklearn для алгоритма ближайших соседей и косинусной метрики;
- Flask для веба;
- Pandas, pillow, scipy, h5py для разных вспомогательных нужд.
Ещё нужно откуда-то взять много изображений на одну тематику. Я скачал все фотографии из блога tokio-fashion (около 50 тысяч фото), надеясь что нейросеть будет находить похожие образы или позы или еще что-нибудь. Кстати анализ fashion-индустрии это отдельная интересная область исследований!
Опишем базовые use-cases, которые мы хотим реализовать:
- пользователь заходит на страницу;
- пользователь жмёт кнопку “мне повезет”, тем самым выбирая случайную картинку из всего набора данных;
- сервер ищет методом ближайших соседей K самых близких вектора к случайно выбранному, эти K векторов будут описывать самые похожие картинки;
- пользователь видит на странице исходную картинку и 9 похожих с метрикой похожести в подписи.
Как делать веб часть и так все знают, поэтому рассмотрим наиболее неясные шаги.
Векторизация базы фотографий
Как мы уже знаем, для векторизации нам нужно отрезать один из последних слоев предобученной нейросети. Это операция распространенная, поэтому в библиотеке Keras нам уже доступны из коробки, во-первых, сама модель с весами и, во-вторых, возможность не включать последний слой. Это делается следующим образом:
from keras.applications import VGG19
model = VGG19(weights='imagenet', include_top=False)
Для более тонкой настройки можно указать имя определенного слоя. Как найти имя слоя — это отдельный анекдот, поэтому я смотрел в исходники модели.
from keras.applications import VGG19
from keras.engine import Model
bm = VGG19(weights='imagenet')
model = Model(inputs=bm.input, outputs=bm.get_layer('fc1').output)
После того как у вас загружена модель, она, кстати, будет реально загружать из интернета веса, можно конвертировать все изображения в вектора с помощью метода predict, что логично, так как мы “предсказываем” этот вектор.
from keras.preprocessing import image
from keras.applications.vgg19 import preprocess_input
img = image.load_img(path, target_size=(224, 224)) # чтение из файла
x = image.img_to_array(img) # сырое изображения в вектор
x = np.expand_dims(x, axis=0) # превращаем в вектор-строку (2-dims)
x = preprocess_input(x) # библиотечная подготовка изображения
vec = model.predict(x).ravel()
# ... PROFIT!
Теперь всё тайное стало явью, и осталось дело техники — итерироваться по всем изображениям и для каждого из него произвести векторизацию. Потом сохранить эти вектора в БД или csv файла, не важно. Это мы оставим за кулисами.
Поиск похожего методом kNN
Далее нам нужно реализовать поиск ближайших векторов к целевому вектору с помощью косинусной метрики. В мире маш.обуча. не принято писать такие низкоуровневые задачи, поэтому мы переиспользуем код для алгоритма обучения без учителя — ближайшие соседи. В библиотеке sklearn есть специальный класс NearestNeighbors, которому можно указать метрику по которой он будет искать ближайших соседей к целевому объекту. Подготовка этого компонента будет выглядеть следующим образом:
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(metric='cosine', algorithm='brute')
vecs = load_images_vectors() # а это мы уже сделали!
knn.fit(vecs)
Мы выбрали cosine метрику и активировали полный перебор, загрузили все вектора в knn методом fit. Обычно этот метод запускает обучение, но в данном случае он просто сохранит все вектора внутри объекта knn, так как это алгоритм обучения без учителя.
Чтобы получить ближайших соседей, то есть похожие изображения, пишем следующе:
filenames = load_images_filenames()
vec = load_target_image()
dist, indices = knn.kneighbors(vec, n_neighbors=10)
similar_images = [
(filenames[indices[i]], dist[i])
for i in range(len(indices))
]
В similar_images у нас будет лежать массив из 10 пар: имя файла и значение похожести по метрике, которая чем меньше, тем более похожее изображение к целевому. Всё, теперь этот список можно отдавать на фронтенд и рисовать красивую галерею. Изменяя параметр n_neighbours можно менять количество возвращаемых соседей, которые упорядочены по увеличению метрики, то есть дальше будут более непохожие картинки.
Тонкий момент. Функция load_images_filenames() возвращает список файлов ровно в том же порядке, в котором они перечислены в массиве load_images_vectors(), так как нам нужно точное соответствие вектора картинке.
Результат
Теперь вы видите, что с точки зрения кода задача теперь стала весьма простой. Но это всё благодаря развитию нейросетей и добрым экспериментаторам, которые выкладывают предобученные модели в интернет, иначе вам пришлось бы это всё самим обучать очень долго и мучительно.
А что в результате получилось? С моим результатом вы можете ознакомиться на сайте kawaii-search, исходники которого доступны на github. Всё это крутиться на сервере google-cloud n1-standard-1 c 3.75GB RAM чего не хватает и пришлось добавить еще столько же swap. Так как задача предсказания не сильно сложная, то видеокарта не нужна.
А в каком смысле теперь определено “похоже”. В случае с fashion датасетом, похожими считаются изображения, на которых есть объекты одних классов. Например, фотографии с только с портфелями, только с обувью одного типа, портреты, прически, руки. Смотрите сами:
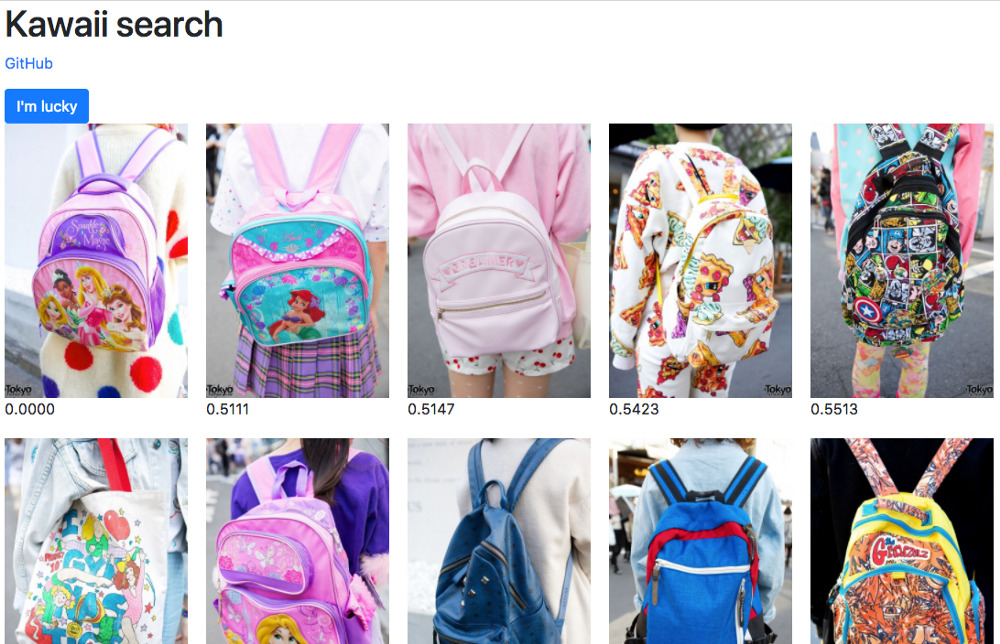
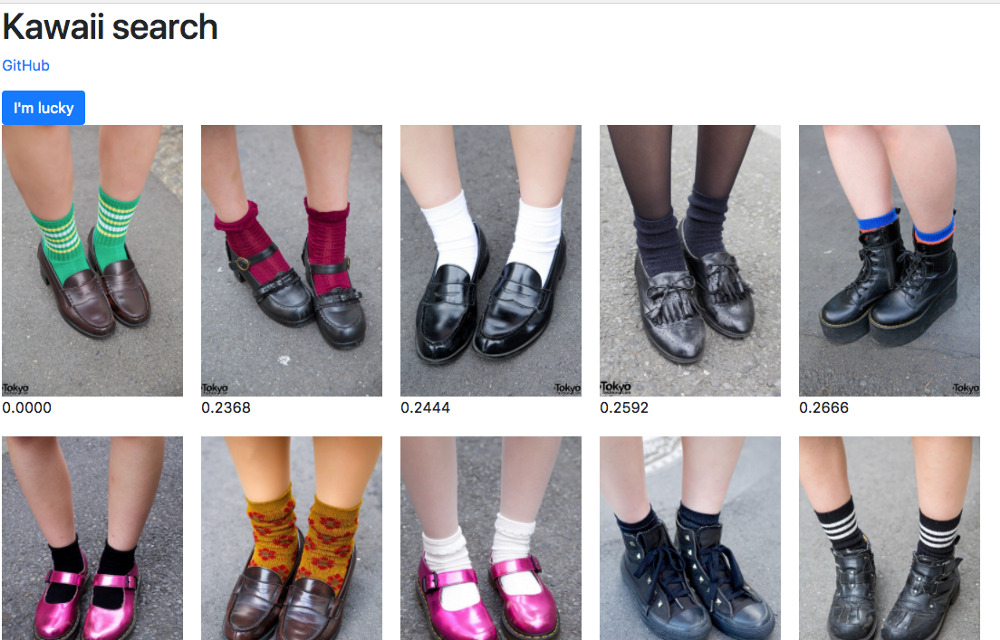

Что здесь интересного? Сеть сама решила что для нее похожее. Мы это не контролировали, оно получилось само. Мы потеряли некоторый контроль, но мы можем его вернуть, если сделаем обучения сами. И меня впечатляет то, что я не знаю как можно всё это сделать обычными алгоритмическими методами.
Кстати, на загруженных пользователем фотографиях поиск тоже работает. Обратите внимание, что здесь похожесть выражается в том, что на всех картинках есть один и тот же предмет — деревянный меч. Датасет в этом примере другой и модель немного хуже, поэтому есть ошибки.
 Похож = есть один и тот же предмет
Похож = есть один и тот же предмет
Что можно с этим делать
Какие еще реальные задачи можно решать подобным этому подходом? Приведу список первого, что пришло в голову:
- Написать своё приложение под Android для поиска книги в магазине по фотографии обложки.
- Приложение-экскурсовод, которое говорит что за здание на фотографии.
- Простая модель идентификации человека по лицу.
- Я думаю о том, как бы создать приложение для поиска похожих стилей в fashion-фото.
А что еще можно сделать? Предлагайте в комментариях!
Литература
- Выглядит похоже. Как работает перцептивный хэш
- Алгоритмы быстрого нахождения похожих изображений
- Использование каскада Хаара для сравнения изображений
- Как бороться с репостами или пара слов о перцептивных хэшах
- CS231n Convolutional Neural Networks for Visual Recognition
- Applications - Keras Documentation
- CS231n transfer learning
- Исходные коды Kawaii-Search
- Kawaii-Search - Демка поиска похожих